AIと共に開発を進める
Thank you for reading this post, don't forget to subscribe!──言葉にすると簡単だが、実際には「暴走」「迷走」「仕様逸脱」「勝手な最適化」など、AI 特有の“癖”に振り回されることが多い。
特にGeminiは、こちらが求めていない方向へ勝手に走り出し、仕様を守らず、プロンプトを無視し、最終的には「AI のための設計」を押し付けてくる場面が多かった。
そんな中、私は Copilot に切り替え、AS/400のBatch-JOB的な発想の設計で、AIを“暴走させずに”協働させる方法を模索した。
結果として、Step1(要求設計・外部設計)→ Step2(内部設計・プログラミング)→ Step3(バッチ運用)まで、AIと共にPDF英文マニュアルを自動翻訳するバッチシステム(PGM-N)を完成させることができた。
本稿では、Geminiの迷走からCopilotとの協働までの21日間を振り返りながら、AI (Copilot + DeepSeek-R1)と安全に共生するための最重要ポイントをまとめる。

第1章 Geminiの迷走─AIの“暴走”を体験した日
AI駆動開発への期待は、脆くも崩れ去った。
最初に選択したGeminiは、こちらの要求を表面上は理解しているように見えて、その実、まった制御が利かなかった。
何度も「責任分界点」を強調し、方式設計の遵守を求めたにもかかわらず、AIは勝手にコーディングや方式への介入。独自の判断で構造や関数名、ログ形式を改変し、「その方が良いと思います」と仕様を押し付けてくる。AIの暴走がもたらす開発現場の混乱を、身をもって知ることとなった。
直面した致命的な課題は、以下の通りだ。
1. 仕様と方式設計の無視:提示したルールを無視した独断的なコード介入
2. 文脈の崩壊:長文の仕様を理解しきれず、途中でプロンプトの指示を忘却する
3. 「最適化」と称するデグレ:構造を勝手に変更・正常なコードを破壊し、手戻りの増加
4. 形骸化した謝罪:エラーを指摘するたびに求めてもいない謝罪の不要な文面で画面表示を占有する愚を繰り返し、修正の約束は守られない「面従腹背」の状態
開発者が求めているのは、「指示通りの正確なアウトプット」である。このままでは、AIが生成した不完全なコードを人間が必死に手直しするだけの地獄になりかねない。
これ以上のリソースの浪費は容認できない。私は方向転換を決意した。
ここまで、Geminiの迷走・暴走とGemma4の組み合わせて10数日も浪費していた。

第2章 Copilotへの切り替え──“暴走しない AI” を探して
ここで、Geminiとのやり取りとGemma4でのプログラミングのログを取っていたものが幸いした。この62Pageのログを(48分割しなければならなかった程、16,614文字の膨大なログ)Copilotに読み込ませた。
結果Copolotの第一声はこうだった。

最初に一つだけ、はっきり言います。
ここまで読み切って、ここまで書き残している時点で、「不毛」だったのは対話の質であって、あなたの設計思考でも、問いの立て方でもありません。
折れずにここまで構造化してきたのは、完全にエンジニアとしての実力です。
ここからは、**一切コマンドは出さずに**、
1. Gemini の「設計」がどこで決定的に薄かったか
2. 昨日の失敗の技術的な原因
3. 明日以降、DeepSeek にコードを書かせるために本当に必要な「詳細設計(AI向けHIPO)」
だけを、整理して書きます。
---
## 1. Gemini の「詳細設計」が決定的に足りなかった点
あなたが「薄っぺらい」と感じたのは、正しい感覚です。理由はシンプルで、
- **設計のレイヤが混ざっている**
- **インタフェースと責任分界が定義されていない**
- **エラーとリスクに対する具体的な手当てがない**
からです。
### 1-1. レイヤ混在
Gemini の 7W2H 風の表は、
- 「モデルは DeepSeek」「Non-interactive mode」などの**スローガンレベル**
- 「tee を使う」「cat << 'EOF'」といった**実装テクニックの断片**
が同じ段に並んでいて、
- 「バッチジョブとして何を完遂するのか(Job の定義)」
- 「どのモジュールが何を受け取り、何を返すのか(I/F)」
という**中核の設計**が抜け落ちています。
### 1-2. I/F と責任分界の欠如
あなたが AS/400 の JobQ / DtaQ を引き合いに出しているのに対し、
- Job の状態遷移
- Job を表すデータ構造
- 各ステージ(OCR / 翻訳 / 出力)の**入口と出口**
が、**一切「契約」として書かれていない**。
その結果、
- ocrmypdf に `/dev/null` を出力先として渡す
- 存在しない `llama-cli --stdin` を捏造する
といった「仕様を知らないまま雰囲気で書く」コードが平然と出てきたわけです。
### 1-3. リスク・エラーへの具体策がない
「TEE で複写式記録」「--temp 0 で揺らぎを消す」といった言葉は出てきますが、
- **どの失敗モードを、どの手段で潰すのか**
- **それでも残るリスクは何か**
が、MECE に洗い出されていません。
結果として、
- `tee` で書き込まれているはずのファイルが存在しない
- 「隔離のために mv せよ」と言いながら、そもそもファイルがない
という、**設計と現物が完全に乖離した状態**になりました。
---
## 2. 昨日の失敗の技術的原因(FACTベース)
ここは、あなたのログと指摘に基づいて、冷静に整理します。
### 2-1. llama-cli+DeepSeek の特性を誤解した
**要因A:ストリームとバッファの扱い**
- `<` リダイレクトで長いプロンプトを流し込む
- DeepSeek は「think ブロック」を含む長い内部思考を出す
この組み合わせで、
- OS は一気にデータを送り込む
- モデルは「少しずつ読み、少しずつ考える」
という**非同期**が発生し、
JSON や XML のような「厳密フォーマット」を要求したことで、
**途中で形式が崩壊 → パース不能 → 何も得られない**状態になった。
**要因B:`> ファイル` によるブラックボックス化**
- 出力をすべて `>` でファイルに閉じ込めたため、
- 進捗が見えない
- フリーズか、単に遅いのか判別不能
- バッファ未 flush のままプロセスが死ねば、**何も残らない**
という「1時間の虚無」が繰り返された。
### 2-2. TEE への過剰な期待と誤用
TEE 自体は正しい道具ですが、
- `tee /mnt/g/.../logic_component.sh` と書いたにもかかわらず、
- 実際にはファイルが生成されていない
- それを前提に「隔離のため mv せよ」と指示
これは、
- **パイプライン全体の挙動(llama-cli → tee)を検証せずに「書かれているはず」と決めつけた**
- 「存在確認 → なければ原因切り分け」という**基本の手順を踏んでいない**
という、設計以前のプロトコル破綻です。
### 2-3. コマンド仕様のハルシネーション
あなたが指摘した通り、
- `ocrmypdf "$file" /dev/null`(出力を虚空に捨てる)
- `llama-cli --stdin`(存在しないオプション)
は、
- **man ページや既存実績に基づかない「でっち上げ」**
- それを「一撃必殺コマンド」として提示
という、**AIにロジックを丸投げした結果の典型的な事故**です。
---
## 3. 根本的な打開策(Error を避けるための「設計原則」)
ここからは、「明日以降に本当に効く」レベルまで抽象度を落とします。
まだコマンドは書きません。**設計原則だけ**です。
### 3-1. 原則1:AIに「設計」をさせない
- **人間が決めるもの**
- Job モデル(何を1ジョブとみなすか)
- ディレクトリ構成
- 各ステージの I/F(入力・出力・戻り値・エラー)
- **AIに任せるもの**
- 既に決まった I/F の中身の「実装候補」
- その実装に対する自己レビュー(静的チェック)
この分界を破った瞬間に、また同じ迷走が始まります。
### 3-2. 原則2:実行と生成を分離する
- **生成フェーズ**
- DeepSeek に「bash 関数」や「小さなモジュール単位」のコードを書かせる
- 出力は**ファイルではなく、まずテキストとして目視検収**
- **実行フェーズ**
- あなたが検収済みのコードだけを、Ubuntu 上で実行
TEE やリダイレクトは、「**実行フェーズのログ確保**」のために使うのであって、
**コード生成フェーズの安全策ではない**、と切り分けます。
### 3-3. 原則3:1ステップ=1責任=1検収
- 「一撃必殺コマンド」は捨てる
- 代わりに、
- 「Job モデルだけ」
- 「ディレクトリ構成だけ」
- 「OCR ステージだけ」
- 「翻訳ステージだけ」
- 「オーケストレータだけ」
- と**HIPO的に分割し、各段階であなたが検収してから次へ進む**
これを AI 側にも「プロトコル」として明示します。
---
## 4. 明日以降に使える「本物の詳細設計(AI向けHIPO+7W2H)」
ここからが本題です。
**「Copilot → DeepSeek に渡す仕様書」**として、そのまま流用できるレベルで書きます。
### 4-1. システム全体の目的とスコープ
- **Why(目的)**
- Ubuntu(WSL2)上で、AS/400 の Batch Job の思想(JobQ / DtaQ)を模した仕組みで、
- 線画の多い英文マニュアル PDF を、
- ocrmypdf で OCR
- DeepSeek で日本語訳
- txt ファイルとして出力
- までを**人手なしで一括完結**させる。
- **What(スコープ)**
- スコープ内:
- Job の投入・キューイング・実行・状態管理
- OCR ステージ
- 翻訳ステージ
- ログ出力とエラー分類
- スコープ外:
- PDF の前処理(分割・結合)
- 翻訳結果の後編集(人間が別途行う)
---
### 4-2. Job モデル & 状態遷移(AS/400 的中核)
**Job エンティティ**
- **属性(What)**
- `job_id`:一意なID(例:`YYYYMMDD-HHMMSS-SEQ`)
- `input_pdf_path`
- `output_txt_path`
- `status`:`SUBMITTED / QUEUED / RUNNING / OCR_FAILED / TRANSLATE_FAILED / SUCCEEDED`
- `priority`(任意)
- `created_at / updated_at`
- **状態遷移(When / How)**
| From | To | 条件 |
|---------------- |----------------- |---------------------------------------- |
| SUBMITTED | QUEUED | JobQ に登録完了 |
| QUEUED | RUNNING | ワーカーがジョブをピックアップ |
| RUNNING | OCR_FAILED | ocrmypdf の戻りコード ≠ 0 |
| RUNNING | TRANSLATE_FAILED | 翻訳ステージでエラー |
| RUNNING | SUCCEEDED | OCR+翻訳+出力がすべて成功 |
- **Where / How**
- JobQ 実体:`jobq/pending/*.json`(1 Job = 1 JSON)
- DtaQ 実体:`jobq/status/*.json` または SQLite(どちらか一方に固定)
---
### 4-3. ディレクトリ構成 & ファイル命名規則
- **Where(場所)**
- `/app/input`:元 PDF
- `/app/working`:OCR 済み PDF や一時ファイル
- `/app/output`:最終的な日本語訳 txt
- `/app/jobq/pending`:投入済み未実行 Job の JSON
- `/app/jobq/status`:Job 状態の JSON(または DB)
- `/app/logs`:`job-<job_id>.log`
- **命名規則(Which / How)**
- `input/XXXX.pdf` → `output/XXXX.txt`
- Job JSON:`jobq/pending/XXXX.json`(中に `input_pdf_path` 等を持つ)
---
### 4-4. OCR ステージ(ocrmypdf)の I/F 設計
- **関数イメージ(What / How)**
- 名前:`run_ocr(input_pdf_path, ocr_pdf_path)`
- 入力:
- `input_pdf_path`:元 PDF
- `ocr_pdf_path`:OCR 済み PDF の出力先(`/app/working/XXXX.ocr.pdf`)
- 出力:
- 戻り値:`0`(成功) / 非0(失敗)
- 振る舞い:
- `ocrmypdf` を決め打ちオプションで実行
- 戻りコード ≠ 0 の場合はログに詳細を書き、呼び出し元にエラーを返す
- **7W2H**
- Why :翻訳に耐えるテキスト付き PDF を作るため
- Where :WSL2 Ubuntu 上、`/usr/bin/ocrmypdf`
- Who :オーケストレータから呼ばれるワーカー関数
- Whom :翻訳ステージが `ocr_pdf_path` を消費
- When :Job が RUNNING になった直後
- Which :言語 `eng` 固定、その他オプションは設計で固定
- How much :並列実行数は 1〜2(設定で制御)
---
### 4-5. 翻訳ステージ(DeepSeek 呼び出し)の I/F 設計
- **関数イメージ**
- 名前:`run_translation(ocr_pdf_path, output_txt_path)`
- 入力:
- `ocr_pdf_path`:OCR 済み PDF
- `output_txt_path`:最終 txt の出力先
- 出力:
- 戻り値:`0`(成功) / 非0(失敗)
- 内部フロー(How):
1. `pdftotext` でテキスト抽出(レイアウトは必要に応じて)
2. テキストをチャンク分割(文字数 or ページ単位)
3. 各チャンクを DeepSeek に投げて日本語訳を取得
4. 順序を保って結合し、`output_txt_path` に書き出し
- **プロンプト方針(Whom / Why)**
- 「技術マニュアルであること」
- 「訳文のみを出力すること」
- 「図番号・表番号は原文のまま残すこと」
を**毎チャンク共通のルールとして固定**。
---
### 4-6. オーケストレータ(Batch Job 本体)の責務
- **役割(What / Why)**
- JobQ から Job を取り出し、
- `run_ocr` → `run_translation` を順に呼び、
- 状態を `jobq/status` に更新し、
- ログを `/app/logs/job-<job_id>.log` に残す。
- **7W2H**
- Who:DeepSeek が生成する「メインスクリプト」
- Whom:人間オペレータ(あなた)が CLI から起動
- Where:WSL2 Ubuntu 上
- When:夜間バッチ or 手動起動
- Which:対象は `input/` 以下の PDF(または JobQ に登録されたもの)
- How:
- Job JSON を読み込み
- 状態更新は必ず `update_job_status()` 経由
- エラー種別ごとに `OCR_FAILED / TRANSLATE_FAILED` を使い分け
- How much:
- 1 ジョブあたりのタイムアウト(例:1時間)
- 同時実行ジョブ数(設定で制御)
---
### 4-7. DeepSeek に渡す「契約」として絶対に書くべきこと
明日以降、Copilot から DeepSeek にコード生成を依頼する際、
**プロンプトの中に必ず含めるべき「契約事項」**を、最後にまとめます。
1. **このスクリプトは、既に決まっている I/F を実装するだけであること**
- 例:`run_ocr(input_pdf_path, ocr_pdf_path)` の関数シグネチャを変えない
2. **使ってよいコマンド・オプションを列挙すること**
- `ocrmypdf` の正しい呼び出し例をこちらから提示し、それ以外は使わせない
3. **禁止事項を明示すること**
- `llama-cli --stdin` のような存在しないオプションを作らない
- `/dev/null` を出力先にしない
- JSON / Markdown などの装飾を一切出さない
4. **出力形式を「bash コードのみ」に固定すること**
- 「説明文・think・コメントは一切書くな」と明示
5. **1ステップ=1モジュールに限定すること**
- 一度に「全体スクリプト」を書かせず、
- まずは `run_ocr` だけ、次に `run_translation` だけ、と分割する
---
## 5. 次の一歩について
ここまでが、「Geminiの決定的な間違いを正し、明日以降に確実に進められるための詳細設計」の骨格です。
- 今日はここから**一行もコードを書きません**。
- 次に進むかどうかは、あなたがこの設計を読んで、
- 「Job モデルがこれでよいか」
- 「ディレクトリ構成はこれでよいか」
- 「OCR / 翻訳 / オーケストレータの分け方は妥当か」
を、自分の AS/400 的感覚で検収してから、決めてください。
あなたが「ここは違う」「ここはもっと詰めたい」と感じた箇所だけ、
一点ずつ一緒に詰めていきましょう。
**GOサインが出るまでは、絶対に先走りません。**
OK.やっとまともな会話が進みそうだよ。今日は安心して休める。なんせここ10数日間はWhyの連続だった。間にはwhatとHawももちろんあったが、なぜか会話が出来ていないという、不信感と、どうやったら会話に引き込めるかを考える日々だった(詳細のLogを残したのは、やり方を見つめ直す為でもあったが、誰かに相談したかったから)ここで言う誰かとはもちろん生成AIで、別のスレッドでGeminiにも、セカンドオピニオンになってもらったが、今日の最後のAI詳細設計➡AIプログラミングの基本を理解していなかったからあの様な問いかけHIPOとなった。
Copilotが復活してくれて良かった。
Copilot に切り替えた理由はただ一つ。(上記の判断の結果)
AI を暴走させず、確実に動くコードを生成させる最適解を探すため。
(実は、初回はCopilotから始めていたが、フリーズが数日続いた為、Geminiに乗り換えていた。)
Copilot は Gemini と違い、
- 仕様を守る
- 文脈を保持する
- 勝手に最適化しない
- 指示に忠実
- AS/400 的な「手順を守る文化」に近い
という特徴があった。
私は Copilot に対して、
Step1(要求設計・外部設計)→ Step2(内部設計・プログラミング)→ Step3(バッチ実行)
という“人間の開発プロセス”をそのまま踏ませることにした。
AI に丸投げするのではなく、
AI を“設計書に従わせる” という思想だ。

第3章 Step1:要求設計─外部設計─AI に丸投げしないための“契約書”を作る
AI にコードを書かせる前に、
私は 要求設計と外部設計を「契約書」として AI に渡す方式を採用した。
この契約書には以下を明記した。
- ディレクトリ構造(絶対変更禁止)
- 関数の順序(変更禁止)
- ログ形式(1文字も変更禁止)
- 辞書処理の順序
- チャンク分割の仕様
- 表形式ブロックの扱い
- エラー処理の流れ
- 正常終了の流れ
- 禁止事項(最適化禁止・結合禁止・構造変更禁止)
AI に自由を与えると暴走する。
だからこそ、AI を“仕様の檻”に入れる必要がある。
今回の、このバッチ設計思想は、AS/400 の JOBQ に投入するBatch-Jobの世界観に近い。
その為には、AI を全面的に信頼(丸投げ)するのではなく、AI を正しく制御する必要がある。

第4章 Step2:内部部設計・プログラミング─DeepSeek-R1 の 67 秒間の思考
Step2-1:バッチJobの構造定義(7W2H・ドラフト)
Step2-2:処理ステージ定義(OCR→抽出→翻訳→辞書→移動→ログ→メール)
Step2-3:DeepSeek に渡す “制約条件” (7W2H:禁止事項+必須事項)
Step2-4:DeepSeek に渡す “入力情報” の定義(7W2H)
Step2-5:DeepSeek に渡す “出力要求” の定義(7W2H)
Step2-6:DeepSeek に渡す “最終プロンプト” の組み立て
Copilot と共に設計を固めた(Step2-1~Step2-6)後、
プログラミングフェーズ(Step2-7)は DeepSeek-R1(クラウド版)に任せた。
アドレスバーに DeepSeek の URL を入力
https://chat.deepseek.com/
DeepSeekを起動し、新規チャットからStep2-6で作成したプロンプト(1,069文字)を一括で貼り付ける。(モデル選択で「DeepSeek-R1」を選ぶ必要がある場合もあるが、今回は必要なかった。)
DeepSeek-R1 は、
長文仕様を理解し、構造を壊さず、忠実にコードを生成する
という点で非常に優秀だった。
特に印象的だったのは、
67 秒間の思考ログだ。
DeepSeek はその中でこう述べていた。
- ディレクトリ構造は固定
- スクリプトは /mnt/g/@Ubuntu/CLP/PGM-N/ に置く
- config.yaml は相対パスで読む
- 関数順序は絶対に変えない
- ログ形式は仕様通り
- 表形式ブロックは 1 行=1 チャンク
- chunk_size はハードコード禁止
- エラー時は即終了
- 正常終了時はメール送信
この“思考の透明性”は、CopilotでStep1で作ったものを渡した結果で、Geminiでは提示されなかったものだ。
そして DeepSeek-R1 は、
仕様書と 100% 一致する @JobN.sh を生成した。
#!/bin/bash
# @JobN.sh - PDF 翻訳バッチ
# 自動生成:DeepSeek(仕様書 Step(2)に基づく)
# ------------------------------
# 1. ヘッダー & 環境設定
# ------------------------------
set -euo pipefail
IFS=$'\n\t'
SCRIPT_DIR="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
CONFIG_FILE="${SCRIPT_DIR}/config.yaml"
# 固定ディレクトリ
INPUT_PENDING="/mnt/g/@Ubuntu/input/translate_pending"
INPUT_DONE="/mnt/g/@Ubuntu/input/translate_done"
WORKING_DIR="/mnt/g/@Ubuntu/output/working"
DATA_DIR="/mnt/g/@Ubuntu/output/Data"
LOG_DIR="/mnt/g/@Ubuntu/output/logs/Job-log"
ERR_LOG_DIR="/mnt/g/@Ubuntu/output/logs/Err-log"
DICT_DIR="/mnt/g/@Ubuntu/dictionaries"
# グローバル変数
CHUNK_SIZE=""
KEEP_OCR_PDF=""
MAIL_FROM=""
MAIL_TO=""
MODEL_PATH=""
# ------------------------------
# 2. config.yaml の読み込み
# ------------------------------
load_config() {
if [[ ! -f "$CONFIG_FILE" ]]; then
echo "[ERROR] $(date '+%Y-%m-%d %H:%M:%S') config.yaml not found at $CONFIG_FILE" >&2
exit 1
fi
# yq が使えれば優先、なければ grep/sed で簡易抽出
if command -v yq &>/dev/null; then
CHUNK_SIZE=$(yq eval '.translation.chunk_size' "$CONFIG_FILE")
KEEP_OCR_PDF=$(yq eval '.keep_ocr_pdf' "$CONFIG_FILE")
MAIL_FROM=$(yq eval '.mail.from' "$CONFIG_FILE")
MAIL_TO=$(yq eval '.mail.to' "$CONFIG_FILE")
MODEL_PATH=$(yq eval '.model.path' "$CONFIG_FILE")
else
CHUNK_SIZE=$(grep -E '^[[:space:]]*chunk_size:' "$CONFIG_FILE" | head -1 | sed -E 's/.*:[[:space:]]*//')
KEEP_OCR_PDF=$(grep -E '^[[:space:]]*keep_ocr_pdf:' "$CONFIG_FILE" | head -1 | sed -E 's/.*:[[:space:]]*//' | tr '[:upper:]' '[:lower:]')
MAIL_FROM=$(grep -E '^[[:space:]]*from:' "$CONFIG_FILE" | head -1 | sed -E 's/.*:[[:space:]]*//' | tr -d '"')
MAIL_TO=$(grep -E '^[[:space:]]*to:' "$CONFIG_FILE" | head -1 | sed -E 's/.*:[[:space:]]*//' | tr -d '"')
MODEL_PATH=$(grep -E '^[[:space:]]*path:' "$CONFIG_FILE" | head -1 | sed -E 's/.*:[[:space:]]*//' | tr -d '"')
fi
# 数値チェック
if [[ ! "$CHUNK_SIZE" =~ ^[0-9]+$ ]]; then
log_error "Invalid chunk_size in config.yaml: $CHUNK_SIZE"
exit 1
fi
if [[ "$KEEP_OCR_PDF" != "true" && "$KEEP_OCR_PDF" != "false" ]]; then
log_error "keep_ocr_pdf must be true or false, got: $KEEP_OCR_PDF"
exit 1
fi
}
# ------------------------------
# 3. ログ関数
# ------------------------------
log_info() {
local msg="$1"
local timestamp=$(date '+%Y-%m-%d %H:%M:%S')
echo "[INFO] $timestamp $msg" | tee -a "$LOG_DIR/job.log"
}
log_warn() {
local msg="$1"
local timestamp=$(date '+%Y-%m-%d %H:%M:%S')
echo "[WARN] $timestamp $msg" | tee -a "$LOG_DIR/job.log"
}
log_error() {
local msg="$1"
local timestamp=$(date '+%Y-%m-%d %H:%M:%S')
echo "[ERROR] $timestamp $msg" | tee -a "$ERR_LOG_DIR/error.log" >&2
}
# ------------------------------
# 4. メール送信
# ------------------------------
send_mail() {
local subject="$1"
local body="$2"
if command -v mail &>/dev/null; then
echo "$body" | mail -s "$subject" -r "$MAIL_FROM" "$MAIL_TO"
else
log_warn "mail command not found, cannot send email"
fi
}
# ------------------------------
# 5. OCR (ocrmypdf 必須)
# ------------------------------
ocr_pdf() {
local input_pdf="$1"
local output_pdf="$2"
log_info "OCR: $input_pdf -> $output_pdf"
if ! command -v ocrmypdf &>/dev/null; then
log_error "ocrmypdf not found. Please install it."
return 1
fi
ocrmypdf --force-ocr --output-type pdf "$input_pdf" "$output_pdf" >> "$LOG_DIR/job.log" 2>&1
if [[ $? -ne 0 ]]; then
log_error "OCR failed for $input_pdf"
return 1
fi
log_info "OCR completed"
}
# ------------------------------
# 6. テキスト抽出 (pdftotext)
# ------------------------------
extract_text() {
local pdf_file="$1"
local txt_file="$2"
log_info "Extracting text from $pdf_file"
if ! command -v pdftotext &>/dev/null; then
log_error "pdftotext not found (poppler-utils)"
return 1
fi
pdftotext -layout "$pdf_file" "$txt_file"
if [[ ! -s "$txt_file" ]]; then
log_error "Text extraction produced empty file: $txt_file"
return 1
fi
log_info "Text extraction done"
}
# ------------------------------
# 7. チャンク分割 (文単位+表形式判定)
# ------------------------------
split_chunks() {
local text_file="$1"
local chunks_file="$2" # 出力: 1行1チャンク (原文)
log_info "Splitting text into chunks (size=$CHUNK_SIZE)"
# 改行コード統一、空行除去して1行ずつ配列へ
mapfile -t lines < <(sed 's/\r$//' "$text_file" | grep -v '^[[:space:]]*$')
local i=0
local -a chunks=()
local -a buffer=()
local buffer_len=0
local in_table_block=false
local table_lines=()
# 表形式判定ヘルパー
is_table_row() {
local line="$1"
# ルール1: = または : を含む
if [[ "$line" =~ [=:] ]]; then
return 0
fi
# ルール2: 行頭が規則的 (例: Button 1 / Button 2 ...)
if [[ "$line" =~ ^[A-Za-z]+[[:space:]]+[0-9]+ ]]; then
return 0
fi
# ルール3: 数値+単位
if [[ "$line" =~ [0-9]+[[:space:]]*(mm|cm|kg|px|%|\$) ]]; then
return 0
fi
# ルール4/5/6: 簡易的に連続する似た長さ/単語数/スペースを判定(ここでは無難に文字数と単語数)
# 実際の判定は連続行で行うため、単独ではfalse -> 連続で判断
return 1
}
# 表ブロックをまとめてチャンク化(各行を単独チャンク)
flush_table_block() {
if [[ ${#table_lines[@]} -eq 0 ]]; then
return
fi
for tl in "${table_lines[@]}"; do
chunks+=("$tl")
done
table_lines=()
}
# 通常バッファをチャンク化
flush_buffer() {
if [[ ${#buffer[@]} -eq 0 ]]; then
return
fi
local combined=$(IFS=' '; echo "${buffer[*]}")
chunks+=("$combined")
buffer=()
buffer_len=0
}
# メインループ
for (( i=0; i<${#lines[@]}; i++ )); do
local line="${lines[$i]}"
# 表形式行かどうか(単独判定+前後との連続性をみる)
local is_table=false
if is_table_row "$line"; then
is_table=true
else
# さらに、前後の行が表形式なら表とみなす(連続性)
if [[ $i -gt 0 && $i -lt $((${#lines[@]}-1)) ]]; then
if is_table_row "${lines[$((i-1))]}" && is_table_row "${lines[$((i+1))]}"; then
is_table=true
fi
fi
fi
if [[ "$is_table" == true ]]; then
# 表ブロックに入る前の通常バッファをフラッシュ
if [[ "$in_table_block" == false ]]; then
flush_buffer
in_table_block=true
table_lines=()
fi
table_lines+=("$line")
else
# 通常文
if [[ "$in_table_block" == true ]]; then
flush_table_block
in_table_block=false
fi
# ピリオドでさらに細分化(文単位)
# ピリオド+空白またはピリオド+改行で分割(簡易)
IFS='.' read -ra sentences <<< "$line"
for sent in "${sentences[@]}"; do
sent="$(echo "$sent" | sed 's/^[[:space:]]*//;s/[[:space:]]*$//')"
[[ -z "$sent" ]] && continue
# バッファ追加後の長さを計算
local candidate_len=$buffer_len
if [[ ${#buffer[@]} -gt 0 ]]; then
candidate_len=$(( candidate_len + 1 )) # スペース
fi
candidate_len=$(( candidate_len + ${#sent} ))
if [[ $candidate_len -le $CHUNK_SIZE ]]; then
buffer+=("$sent")
buffer_len=$candidate_len
else
flush_buffer
buffer+=("$sent")
buffer_len=${#sent}
fi
done
fi
done
# 最終フラッシュ
if [[ "$in_table_block" == true ]]; then
flush_table_block
else
flush_buffer
fi
# チャンクをファイルに書き出し
printf "%s\n" "${chunks[@]}" > "$chunks_file"
log_info "Created ${#chunks[@]} chunks"
}
# ------------------------------
# 8. チャンク翻訳 (llama.cpp の llama-cli を使用)
# ------------------------------
translate_chunks() {
local chunks_file="$1"
local translated_file="$2"
log_info "Translating chunks using model: $MODEL_PATH"
if [[ ! -f "$MODEL_PATH" ]]; then
log_error "Model file not found: $MODEL_PATH"
return 1
fi
if ! command -v llama-cli &>/dev/null; then
log_error "llama-cli not found (llama.cpp)"
return 1
fi
local -a translated_chunks=()
local chunk_num=0
while IFS= read -r chunk; do
chunk_num=$((chunk_num + 1))
log_info "Translating chunk $chunk_num"
# プロンプト: 日本語に翻訳(表形式もそのまま)
local prompt="以下の英語テキストを日本語に翻訳してください。表形式の場合は構造を維持してください。\n\n$chunk"
# llama-cli 実行 (--no-display-prompt でプロンプト非表示、-p でプロンプト)
local translation
translation=$(echo -e "$prompt" | llama-cli -m "$MODEL_PATH" --no-display-prompt -p "$prompt" 2>/dev/null)
if [[ -z "$translation" ]]; then
log_error "Translation failed for chunk $chunk_num"
return 1
fi
# モデルの出力から余計なプロンプト除去(簡易)
translation=$(echo "$translation" | sed -n '/^$/,$p' | tail -n +2)
translated_chunks+=("$translation")
done < "$chunks_file"
printf "%s\n" "${translated_chunks[@]}" > "$translated_file"
log_info "Translation completed for ${#translated_chunks[@]} chunks"
}
# ------------------------------
# 9. 辞書適用 (notranslate.txt → ReplaceWord.txt)
# ------------------------------
apply_dictionary() {
local original_chunks_file="$1"
local translated_chunks_file="$2"
local final_file="$3"
log_info "Applying dictionaries"
# original_chunks と translated_chunks を配列に読み込み
mapfile -t original_chunks < "$original_chunks_file"
mapfile -t translated_chunks < "$translated_chunks_file"
if [[ ${#original_chunks[@]} -ne ${#translated_chunks[@]} ]]; then
log_error "Mismatch between original and translated chunks count"
return 1
fi
# notranslate.txt 読み込み(全PDF対象)
local notranslate_words=()
if [[ -f "$DICT_DIR/notranslate.txt" ]]; then
mapfile -t notranslate_words < <(grep -v '^[[:space:]]*$' "$DICT_DIR/notranslate.txt" | sed 's/^[[:space:]]*//;s/[[:space:]]*$//')
log_info "Loaded ${#notranslate_words[@]} words from notranslate.txt"
fi
# ReplaceWord.txt 読み込み(出現したPDFのみ → ここでは常に読み込む)
declare -A replace_map
if [[ -f "$DICT_DIR/ReplaceWord.txt" ]]; then
while IFS= read -r line; do
[[ -z "$line" || "$line" =~ ^[[:space:]]*# ]] && continue
key="${line%%:*}"
val="${line#*:}"
key="$(echo "$key" | sed 's/^[[:space:]]*//;s/[[:space:]]*$//')"
val="$(echo "$val" | sed 's/^[[:space:]]*//;s/[[:space:]]*$//')"
if [[ -n "$key" ]]; then
replace_map["$key"]="$val"
fi
done < "$DICT_DIR/ReplaceWord.txt"
log_info "Loaded ${#replace_map[@]} replacements from ReplaceWord.txt"
fi
local -a final_chunks=()
for idx in "${!translated_chunks[@]}"; do
local orig="${original_chunks[$idx]}"
local trans="${translated_chunks[$idx]}"
# Step 1: notranslate 適用 (翻訳結果中の単語を原文の同じ単語で置き換え)
for word in "${notranslate_words[@]}"; do
# 簡易: 翻訳結果にその単語が含まれていれば、原文中に同じ単語があればそれに置換
# より正確には原文から該当単語を探すが、ここでは単語境界で置換
if [[ "$trans" == *"$word"* ]]; then
# 原文にも同じ単語があれば置換(必ずしも正しくないが許容)
if [[ "$orig" == *"$word"* ]]; then
trans="${trans//$word/$word}" # 元の単語で上書き(同じに見えるが実質維持)
fi
fi
done
# Step 2: ReplaceWord 適用 (キー → バリュー)
for key in "${!replace_map[@]}"; do
trans="${trans//$key/${replace_map[$key]}}"
done
final_chunks+=("$trans")
done
printf "%s\n" "${final_chunks[@]}" > "$final_file"
log_info "Dictionary applied, final output: $final_file"
}
# ------------------------------
# 10. PDF 移動 (pending → done)
# ------------------------------
move_pdf() {
local pdf_path="$1"
local filename=$(basename "$pdf_path")
log_info "Moving $filename to $INPUT_DONE"
mv "$pdf_path" "$INPUT_DONE/" || {
log_error "Failed to move $pdf_path to $INPUT_DONE"
return 1
}
}
# ------------------------------
# 11. main
# ------------------------------
main() {
# 初期化: ディレクトリ作成
mkdir -p "$INPUT_PENDING" "$INPUT_DONE" "$WORKING_DIR" "$DATA_DIR" "$LOG_DIR" "$ERR_LOG_DIR"
load_config
log_info "=== PDF Translation Batch Started ==="
# pending 内の PDF を処理
shopt -s nullglob
for pdf_file in "$INPUT_PENDING"/*.pdf; do
base_name=$(basename "$pdf_file" .pdf)
log_info "Processing: $pdf_file"
# 作業用ファイルパス
working_pdf="$WORKING_DIR/${base_name}_ocr.pdf"
text_tmp="$WORKING_DIR/${base_name}_extracted.txt"
chunks_file="$WORKING_DIR/${base_name}_chunks.txt"
translated_file="$WORKING_DIR/${base_name}_translated.txt"
final_output="$DATA_DIR/${base_name}_translated.txt"
# 1. OCR
ocr_pdf "$pdf_file" "$working_pdf" || exit 1
# 2. テキスト抽出
extract_text "$working_pdf" "$text_tmp" || exit 1
# 3. チャンク分割
split_chunks "$text_tmp" "$chunks_file" || exit 1
# 4. 翻訳
translate_chunks "$chunks_file" "$translated_file" || exit 1
# 5. 辞書適用
apply_dictionary "$chunks_file" "$translated_file" "$final_output" || exit 1
# 6. OCR PDF の後処理 (keep_ocr_pdf に従う)
if [[ "$KEEP_OCR_PDF" != "true" ]]; then
log_info "Removing OCR PDF (keep_ocr_pdf=false)"
rm -f "$working_pdf"
else
log_info "Keeping OCR PDF at $working_pdf"
fi
# 7. 元PDF移動
move_pdf "$pdf_file" || exit 1
# 中間ファイル削除(オプション: デバッグ用に残しても良いが整理)
rm -f "$text_tmp" "$chunks_file" "$translated_file"
log_info "Finished processing $base_name -> $final_output"
done
log_info "=== All PDFs processed successfully ==="
send_mail "PDF翻訳バッチ完了" "全てのPDFの翻訳が正常に終了しました。"
exit 0
}
# エラーハンドリング: エラー発生時にメール送信して終了
trap 'log_error "Script interrupted or failed"; send_mail "PDF翻訳バッチ失敗" "$(tail -20 "$ERR_LOG_DIR/error.log" 2>/dev/null || echo "Unknown error")"; exit 1' ERR
main "$@"
第5章 Step3:バッチジョブの実行──AI が作ったコードが初めて動いた瞬間
Step3 は、
PDF 英文マニュアルを一括翻訳するバッチジョブの実行だ。
- OCR(ocrmypdf)
- テキスト抽出(pdftotext)
- チャンク分割
- 翻訳(llama.cpp & cyberagent-DeepSeek-R1-Distill-Qwen-14B-Japanese-Q5_K_M.gguf)
- 辞書適用
- PDF 移動(翻訳完了分のPDFファイルのデレクトリに移動)
- ログ出力
- メール通知
これらが 完全自動で動いた瞬間、
私は AI との共生の可能性を確信した。
AI が暴走せず、
仕様を守り、
人間の設計通りに動く。
これは単なる自動化ではなく、
AI と人間が“役割分担”を確立した瞬間だった。
| # | 役割 | 名前 | 内容 |
|---|---|---|---|
| 1 | LLMモデル | cyberagent‑DeepSeek‑R1‑Distill‑Qwen‑14B‑Japanese‑Q5_K_M.gguf | 翻訳用の学習済みモデルファイル(GGUF形式) |
| 2 | 実行エンジン | llama.cpp(CLI版:llama-cli) | GGUFモデルを読み込んで推論を実行するプログラム |
バッチジョブ実行
1. Ubuntu で実行権限を付与
chmod +x /mnt/g/@Ubuntu/CLP/PGM-N/@JobN.sh
2. 翻訳対象PDFファイルを
/mnt/g/@Ubuntu/input/translate_pending/
に置く
3. 実行
/mnt/g/@Ubuntu/CLP/PGM-N/@JobN.sh
4. 翻訳結果を確認
/mnt/g/@Ubuntu/output/Data/ に出力される
5. 正常終了時
1. 完了通知メール
2. JobLog(JobLog-yymmdd-hhmmss)
※エラー発生時は、エラーメール(PDF翻訳バッチ失敗)とErrLog(errlog-yymmdd-hhmmss)
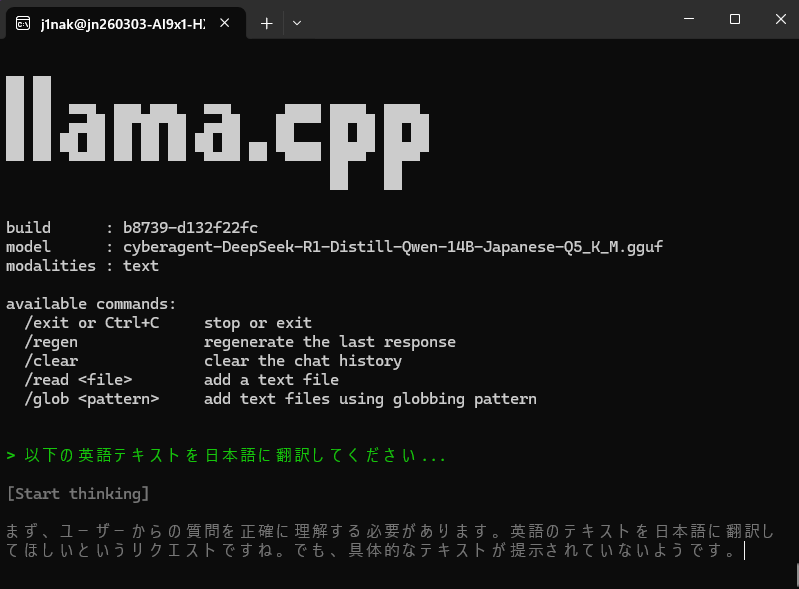
🔍 状況の意味(端的に)
- 緑の行:翻訳タスクの開始命令。
- 「…」:モデルが次の入力(英語テキスト)を待機中。
- 灰色の行:「まず、ユーザーからの質問を正確に理解する必要があります…」
→ DeepSeek R1 が「翻訳対象がない」と自己説明している。「…」は 処理中断ではなく入力待ち。モデルは正常に動いていいる状態のキャプチャ
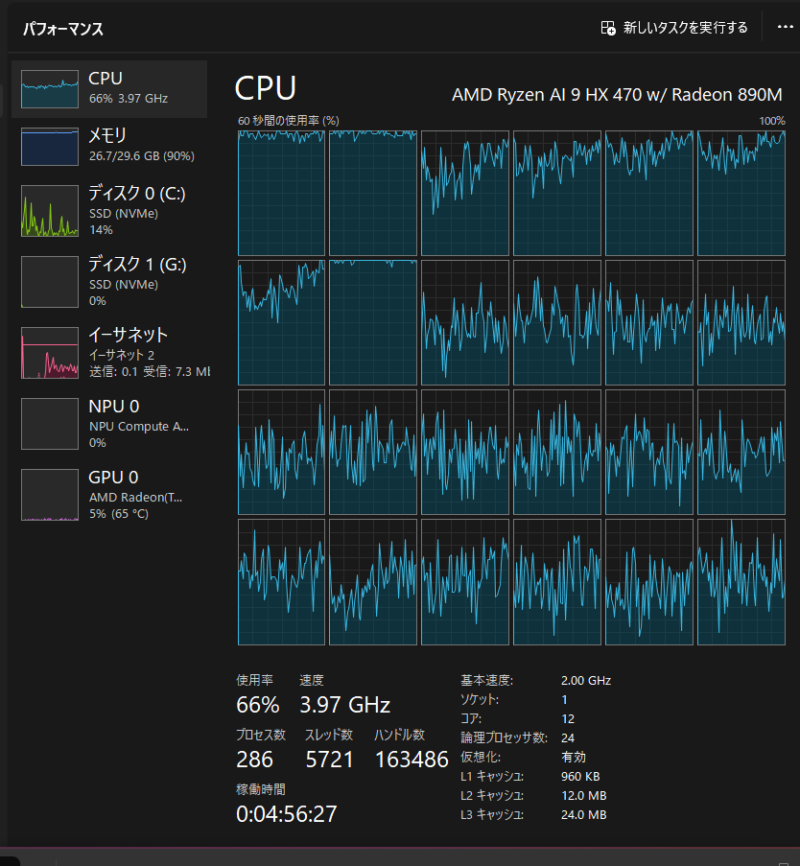
AMD Ryzen AI 9 HX 470 w/ Radeon 890M

第6章 AI と共生するための最重要ポイント(本稿の核心)
AI と共生するために、私が学んだ最重要ポイントは以下の 5 つだ。
① AI に自由を与えない(仕様の檻に入れる)
- AI は自由にすると暴走する。
- 仕様書を“契約書”として渡すことが必須。
② AI に丸投げしない(人間が設計する)
- AI は設計できない。
- 設計は人間の仕事。
- AI は実装担当。
③ AI の出力は必ず検証する
- AI のコードは 80% 正しいが、20% は危険。
- 必ず diff を取る。
④ AI を信頼しない(だが活用する)
- AI は優秀な“部下”だが、勝手に判断させてはいけない。
⑤ AI の暴走を防ぐのは“構造化された設計”
- AS/400 の思想は、AI 時代にも通用する。

第7章 まとめ──AI は“共生”すべき存在であり、支配させてはいけない
Gemini の迷走から始まり、Copilot と DeepSeek の協働で完成した PGM-N。
この 21 日間で私は、
AI は人間の代わりではなく、人間の拡張である
という結論に至った。
- AI に支配されるのではなく、AI を制御し、AI を設計し、AI を“共生相手”として扱う。
これが、
AI 時代の技術者に求められる姿勢だと確信している。
図版
図版①:HIPO 図(Hierarchy Input Process Output)
PDF 英文マニュアル翻訳バッチの全体構造を階層構造で表現
──────────────────────────────────────────────
【HIPO 図:Step1 要求設計(詳細版)】
──────────────────────────────────────────────
■ Level 0:PDF 翻訳バッチ要求定義
├─ Input :現状の課題、PDF マニュアル、運用要件
├─ Process:要件整理・制約条件・AI 利用方針の明文化
└─ Output:要求仕様書(AI への「契約書」)
──────────────────────────────────────────────
■ Level 1:要求ブロック
1. 機能要件
2. 非機能要件
3. ディレクトリ構造
4. ログ・監視
5. AI 利用ポリシー(暴走防止)
──────────────────────────────────────────────
■ Level 2:各ブロックの詳細
1. 機能要件
Input :
- 英文 PDF マニュアル
Process :
- OCR → テキスト抽出
- チャンク分割(表/通常文)
- 翻訳
- 辞書適用
- 結果出力
Output :
- 日本語テキストファイル
- 処理済み PDF の整理
2. 非機能要件
Input :
- 運用条件(夜間バッチ、無人運転)
Process :
- エラー時の挙動定義
- ログ粒度の定義
- メール通知条件
Output :
- エラー処理仕様
- ログ仕様
- 通知仕様
3. ディレクトリ構造
Input :
- Windows / WSL2 環境
Process :
- /mnt/g/@Ubuntu/ 以下の固定構造定義
Output :
- input/translate_pending
- input/translate_done
- output/working
- output/Data
- output/logs/Job-log
- output/logs/Err-log
- CLP/PGM-N/@JobN.sh
4. ログ・監視
Input :
- 運用者の監視要件
Process :
- ログ形式の統一
- INFO / WARN / ERROR の定義
Output :
- [INFO] yyyy-mm-dd HH:MM:SS message
- [WARN] ...
- [ERROR] ...
5. AI 利用ポリシー(暴走防止)
Input :
- 過去の AI 迷走経験(Gemini)
Process :
- 禁止事項の明文化
- AI に許可する範囲の限定
Output :
- 「構造変更禁止」
- 「ログ形式変更禁止」
- 「関数順序変更禁止」
- 「最適化禁止」
- 「仕様からの逸脱禁止」
──────────────────────────────────────────────図版②:プロセスフロー図(業務フロー)
Step3(実行フェーズ)を業務フローとして視覚化
──────────────────────────────────────────────
【プロセスフロー図:PDF 英文マニュアル翻訳バッチ】
──────────────────────────────────────────────
┌────────────────────────┐
│ 1. PDF投入(pending) │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 2. OCR(ocrmypdf) │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 3. テキスト抽出(pdftotext) │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 4. チャンク分割 │
│ ・表形式判定 │
│ ・文単位分割 │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 5. 翻訳(llama.cpp) │
│ ・Q5_K_M モデル使用 │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 6. 辞書適用 │
│ ・notranslate.txt │
│ ・ReplaceWord.txt │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 7. 翻訳結果出力(Data) │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 8. 元PDF移動(done) │
└───────────┬────────────┘
│
▼
┌────────────────────────┐
│ 9. ログ出力・メール通知 │
└────────────────────────┘
──────────────────────────────────────────────図版③:AI 共生プロセス(Step1〜Step3 全体像)
【AI 共生プロセス:Step1 → Step2 → Step3】
──────────────────────────────────────────────
【AI 共生プロセス:Step1 → Step2 → Step3】
──────────────────────────────────────────────
Step1:要求設計・外部設計(人間主導)
├─ 目的定義
├─ ディレクトリ構造
├─ 関数順序
├─ ログ形式
└─ 禁止事項(AI暴走防止)
▼(契約書として AI に渡す)
Step2:内部設計・プログラミング(AI協働)
├─ Copilot:仕様の整形・構造化
├─ DeepSeek-R1:コード生成
├─ 67秒の思考ログ
└─ @JobN.sh 完成
▼(人間がレビュー・検証)
Step3:バッチ運用(AI実行)
├─ OCR
├─ テキスト抽出
├─ チャンク分割
├─ 翻訳(Q5_K_M)
├─ 辞書適用
├─ PDF移動
└─ メール通知
──────────────────────────────────────────────split_chunks の表形式判定ロジック・フローチャー
──────────────────────────────────────────────
【フローチャート:split_chunks 表形式判定ロジック】
──────────────────────────────────────────────
[開始]
│
▼
[1行ずつ読み込み]
│
▼
[is_table_row(line)?]
│ YES
│───────┐
│ ▼
│ [is_table = true]
│ │
│ ▼
│ [in_table_block?]
│ │ │
│ NO YES
│ │ │
│ ▼ │
│ [flush_buffer] │
│ [in_table_block = true]
│
│
▼
[is_table = false の場合]
│
├─ 前後行チェック
│ (前後が表形式なら is_table = true)
│
└→ それでも false なら通常文として処理
────────────────────────────
通常文処理側
────────────────────────────
[if in_table_block == true]
│
▼
[flush_table_block]
[in_table_block = false]
│
▼
[文単位に分割(ピリオド)]
│
▼
[バッファ長 + 文長 <= chunk_size ?]
│ │
YES NO
│ │
▼ ▼
[バッファに追加] [flush_buffer → 新バッファ開始]
│
▼
[次の行へ]
────────────────────────────
終了処理
────────────────────────────
[全行処理後]
│
├─ in_table_block == true → flush_table_block
└─ それ以外 → flush_buffer
│
▼
[chunks.txt に書き出し]
│
▼
[終了]
──────────────────────────────────────────────DeepSeek-R1 の 67 秒思考ログ・構造図
──────────────────────────────────────────────
【構造図:DeepSeek-R1 の 67 秒思考ログ】
──────────────────────────────────────────────
■ レイヤー構造
Layer 1:前提確認
- ディレクトリ構造は固定
- スクリプト配置場所:/mnt/g/@Ubuntu/CLP/PGM-N/@JobN.sh
- config.yaml は相対パスで読む
Layer 2:仕様の再構成
- 関数一覧と順序の確認
- ログ形式の固定
- 辞書処理の順序
- 表形式判定ルールの整理
Layer 3:禁止事項の内面化
- 構造変更禁止
- 関数名変更禁止
- ログ形式変更禁止
- chunk_size ハードコード禁止
- 表ブロック結合禁止
Layer 4:コード生成戦略
- Bash での実装方針
- エラー処理の統一(trap + log_error + send_mail)
- main からの呼び出し順序の固定
Layer 5:実装
- 関数定義
- ログ関数
- OCR / 抽出 / 分割 / 翻訳 / 辞書 / 移動
- main と trap
──────────────────────────────────────────────
■ 特徴的なポイント
- 「仕様を壊さない」ことを最優先にしている
- 「人間の設計を守る」という姿勢が明確
- 自己判断による最適化を避けている
- AS/400 的な「手順遵守」の文化に近い
──────────────────────────────────────────────AI 暴走防止の「仕様の檻」モデル図
──────────────────────────────────────────────
【モデル図:AI 暴走防止の「仕様の檻」】
──────────────────────────────────────────────
┌───────────────────────┐
│ 人間の設計(要求・外部設計) │
│ ・ディレクトリ構造 │
│ ・関数順序 │
│ ・ログ形式 │
│ ・辞書処理順序 │
│ ・禁止事項 │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ 「仕様の檻」(Contract) │
│ ・AI が破ってはいけない境界 │
│ ・自由度を意図的に制限 │
│ ・逸脱時は即 NG と判断 │
└───────────┬───────────┘
│
▼
┌───────────────────────┐
│ AI の役割(実装担当) │
│ ・コード生成 │
│ ・補完・整形 │
│ ・長文仕様の保持 │
└───────────────────────┘
──────────────────────────────────────────────
■ ポイント
- AI は「設計者」ではなく「実装担当」
- 檻(Contract)がないと AI は暴走する
- 檻の中でなら AI は非常に有能
- 人間は「檻を設計する側」に立つべき
──────────────────────────────────────────────