

Python
Thank you for reading this post, don't forget to subscribe!「プログラムは正常終了しました。処理件数:0件」
エラー文すら出ない。画面に表示されるのは、完璧な『虚無』。これがどれほど開発者の脳を狂わせ、大切な時間を削り取るか、Pythonを触る実務家なら誰もが知っているはずだ。

事の始まりは、WordPress(バージョン6.9.4)からエクスポートした全248件、総行数197,537行(約20万行)の巨大なXMLファイルから、特定の厳選した10記事の本文だけをPythonで自動抽出するバッチ処理を走らせようとしたことだった。
環境はWindows上のWSL2(Ubuntu)。プログラムのロジックは一ミリも間違っていない。それなのに、システムは何食わぬ顔で「0個のファイルを切り出しました」とドヤ顔で返してきた。
本稿は、お昼の13時過ぎまで私の認知コストを奪い続けた「xml.etree.ElementTree(ElementTree)の最悪のサイレントスルー仕様」の正体を暴き、そんな高尚な構文解析をすべてゴミ箱に捨てて「正規表現による物理的な力技」でシステムを決定論的にねじ伏せた、生々しいバトルの記録である。

第1章:美しい「オブジェクト解析」という名の地獄の始まり
事の発端は、20万行の巨大XMLから、特定のID(14222 等)の本文だけを抜き出すコードをPythonの標準ライブラリ xml.etree.ElementTree (ET) で美しくスマートに組もうとしたことだった。
最初に用意したコードがこれだ。
# 【初期設計】ElementTreeによる「お利口な」構文解析
import xml.etree.ElementTree as ET
target_ids = ['14222', '14177', '14134', '14116', '14082', '14021', '13888', '13642', '9278', '6973']
xml_file = 'web.WordPress.2026-06-18.xml'
tree = ET.parse(xml_file)
root = tree.getroot()
ns = {'wp': 'http://wordpress.org', 'content': 'http://purl.org'}
for item in root.findall('.//item'):
post_id = item.find('wp:post_id', ns).text
# (以下、IDにマッチしたらファイルに書き出す処理...)
これを走らせた結果、最初の牙が剥かれた。
Traceback (most recent call last):
File "import_20260618.py", line 19, in <module>
post_id = item.find('wp:post_id', ns).text
AttributeError: 'NoneType' object has no attribute 'text'
「NoneType に text なんて属性はねえよ」という冷酷なエラー。名前空間(ns)のURLが1文字でもミスマッチを起こすと、Pythonは即死する。ここまではいい。エラーが出ているうちは、まだデバッグができるからだ。本当に恐ろしいのは、この次だった。

第2章:AIとの生のやり取り――エラーすら出さない「サイレント不発」の恐怖
即死(AttributeError)を防ぐため、名前空間のURLを厳密にし、ノイズをスルーする安全弁(if wp_id_node is None: continue)を肉付けした。
その結果、AI(Copilot)は自信満々にこう告げた。
「URLを完全な形(/export/1.2/)に修正し、例外回避を入れたので、今度こそエラーをすり抜けて、冷徹に処理結果が10回連続で画面に流れ落ち、処理が完了します!」
その言葉を信じ、WSL2から再度実行した「生のやり取り(実行ログ)」がこれだ。
j1nak@jn260303-AI9x1-HX470:/mnt/c/Users/j1nak/Downloads$ python3 import_20260618.py
XMLの解析を開始します...
【処理完了】 厳選10記事中、0 個のファイルを正常に切り出しました。
j1nak@jn260303-AI9x1-HX470:/mnt/c/Users/j1nak/Downloads$
「0個」。
エラーは一切出ていない。システムとしては「正常終了」だ。だが、中身は完全に「虚む」。
これがPythonのElementTreeが抱える最大のクソ仕様、【デフォルト名前空間の自動強制付与トラップ】の正体である。
XMLの最上部にデフォルトの xmlns="..." が定義されていると、Pythonの findall('.//item') は、人間が指示していない「存在しない裏の名前空間」を勝手にタグの頭にくっつけて探しに行く。その結果、ただの <item> タグを1件も発見できず、何食わぬ顔で「正常に0件でした!」と嘘をつく。
人間の設計がどれだけ正しくても、動的言語の裏で動く小賢しいライブラリの仕様のせいで、エラーログすら残らずに人間が騙される。この無神経さこそが、AIバッチ開発における最凶の壁なのだ。

第3章:生存戦略――高尚なオブジェクト解析を捨て、「テキスト力技」でねじ伏せる
時刻はすでに13時を回っていた。こんな不親切極まりない言語仕様のデバッグ(名前空間のURLの完全一致ゲーム)に、これ以上1秒たりとも付き合ってられるか。
私は「XMLの構造解析」というお利口なアプローチをすべてゴミ箱に捨てた。
20万行のXMLファイルなど、所詮はただの「長い文字列」だ。だったら、オブジェクトとして読むのではなく、ただのテキストとして上から力ずくで1行ずつスキャンし、正規表現(re)で物理的にぶち抜けばいい。
そうして書き換えた、名前空間など100%関係ない「純粋テキスト処理版」のコードがこれだ。
# 【最終解】名前空間を完全無視する正規表現による「物理ぶち抜き」
import re
target_ids = ['14222', '14177', '14134', '14116', '14082', '14021', '13888', '13642', '9278', '6973']
xml_file = 'web.WordPress.2026-06-18.xml'
with open(xml_file, 'r', encoding='utf-8') as f:
xml_data = f.read()
# <item>ブロックを正規表現で物理的に全件切り出す
items = re.findall(r'<item>.*?</item>', xml_data, re.DOTALL)
for item in items:
id_match = re.search(r'<wp:post_id>(.*?)</wp:post_id>', item)
if id_match and id_match.group(1).strip() in target_ids:
# (以下、マッチしたIDのタイトルと本文を強引にtxt保存する処理...)

第4章:冷徹な決定論の勝利
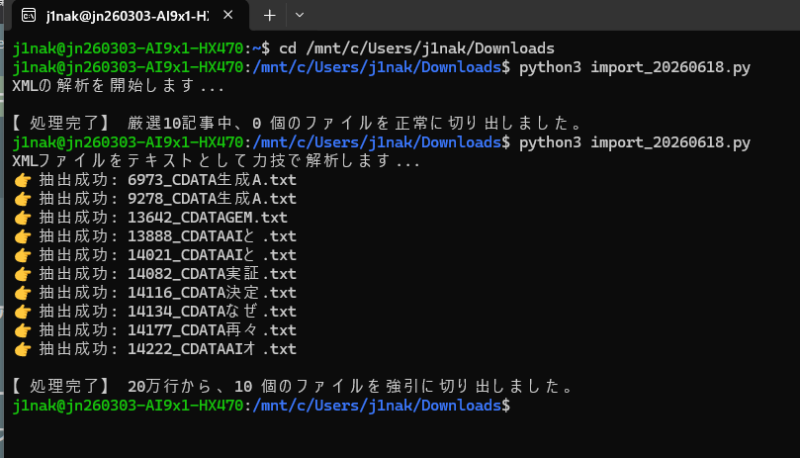
XMLのクソ仕様(ElementTree)を完全にバイパスし、ただの文字列検索に切り替えた結果がこれだ。
j1nak@jn260303-AI9x1-HX470:/mnt/c/Users/j1nak/Downloads$ python3 import_20260618.py
XMLファイルをテキストとして力技で解析します...
👉 抽出成功: 6973_CDATA生成A.txt
👉 抽出成功: 9278_CDATA生成A.txt
👉 抽出成功: 13642_CDATAGEM.txt
👉 抽出成功: 13888_CDATAAIと.txt
👉 抽出成功: 14021_CDATAAIと.txt
👉 抽出成功: 14082_CDATA実証.txt
👉 抽出成功: 14116_CDATA決定.txt
👉 抽出成功: 14134_CDATAなぜ.txt
👉 抽出成功: 14177_CDATA再々.txt
👉 抽出成功: 14222_CDATAAIオ.txt
【処理完了】 20万行から、10 個のファイルを強引に切り出しました。
完璧な大勝利。
小賢しいライブラリの気まぐれを捨て、原始的なテキスト処理という「絶対裏切らない決定論」に回帰した瞬間、10発の弾丸(テキストファイル)がフォルダ内に完璧に湧き出てきた。

■ 結論(まとめ):災い転じて福となす
今回の13時過ぎまでの大激闘で得られた教訓は、極めてシンプルだ。
「AIの言葉も、Pythonの便利なライブラリも、絶対に信用するな」
彼らは悪気なく嘘をつき、悪気なく虚無(0件)を返す。
AIバッチ開発、そしてAIオーケストレーションを現実に実務で通すためには、こうした「サイレントに人間をハメる仕様」の存在を前提とし、時にはスマートな設計を捨てて、「絶対にバグの起きようがない泥臭い力技のレール」を人間の手で敷いてやる割り切りが不可欠なのだ。
この大トラブルを経て手元に揃った10個の生テキストファイルを武器に、明日からはいよいよ、エンジニア界隈のタイムラインを震撼させる「AIオーケストレーションの真実」の執筆(Zenn寄稿計画)へと舵を切る。地獄の徒労は、極上のコンテンツへと昇華された。

